[동정] 서석홍(재경영남대 총동창회 회장)
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
-
1
'아이유 광고'에도 쓰였다…차세대 촬영 기술로 주목받는 '이것'[원종환의 中企줌인]
지난달 31일 경기 파주 문발동에 있는 시각특수효과(VFX)회사 덱스터의 버추얼 프로덕션(가상 제작·VD) 세트장. 현장 감독이 신호를 보내자 성인 남성 2.5배 높이의 ㄷ자형 LED 월에 비행하는 수송기 내부가 펼쳐졌다.이 공간이 홍콩 야시장이나 중동의 사막 등으로 바뀌는 데 걸린 시간은 단 몇 초. 회사 관계자는 “실시간으로 렌더링(2D 이미지를 3D화하는 것)한 배경이 화각에 따라 움직여 실제와 같은 생동감을 구현한다”며 “현장 촬영이 어려운 장소도 손쉽게 대체할 수 있어 활용성이 높다”고 말했다.약 660㎡ 규모의 이 세트장은 영화뿐 아니라 광고나 뮤직비디오, 드라마 등의 여러 미디어 아트를 버추얼 프로덕션으로 구현한 대표적인 장소다. 덱스터는 VFX와 디지털 색보정(DI), 음향 등 영상 제작에 관련한 모든 후처리 공정을 작업할 수 있는 국내 유일 업체다. 영화 넘어 광고, 예능 프로에도 쓰이는 VD버추얼 프로덕션은 시각특수효과와 3D 그래픽 제작 소프트웨어 ‘언리얼 엔진’으로 만들어 낸 가상 세계과 촬영 현장을 결합하는 기법이다. 가상 공간을 구현한 LED 월과 배우를 ‘인카메라 시각특수효과(ICVFX)’를 통해 자연스러운 한 화면에 담아낸다. 명령어 몇 개 만으로 가상 공간 조형물의 위치를 바꾸거나 시간대를 자유롭게 조절할 수 있다.영상 촬영과 동시에 색 보정, 이펙트(효과) 조절 등 후공정을 진행해 감독이 실시간으로 영상 피드백을 하는 것도 가능하다. 회사 관계자는 “촬영 준비 단계부터 감독의 의도에 맞춰 공간을 구현해 작업을 진행할 수 있는 게 장점”이라며 “촬영 세트장을 최소화하거나 날씨
!['아이유 광고'에도 쓰였다…차세대 촬영 기술로 주목받는 '이것'[원종환의 中企줌인]](https://img.hankyung.com/photo/202502/01.39390309.3.jpg)
-
2
'80% 합격률' '수업생 1위' 과장 광고로 공정위 제재받은 공단기
공무원 시험 전문 브랜드 공단기(공무원단기학교)가 거짓·과장 광고로 공정거래위원회로부터 제재를 받았다. 공단기는 '수험서 1위' '매출 1위' '수강생 수 1위' 등 객관적 근거가 없는 광고 문구로 소비자를 오인하게 했다는 지적을 받았다. 3일 공정거래위원회는 공단기 운영사 ㈜에스티유니타스가 거짓·과장·기만 광고를 했다고 보고 시정명령을 하고, 과징금 1억900만원을 부과하기로 결정했다고 밝혔다. 에스티유니타스는 공무원과 공기업 합격을 목표로 하는 성인을 대상으로 온·오프라인 교육 콘텐츠를 제공하는 업체다. 공정위에 따르면 공단기는 2021년 6월부터 두 달 간 전산·사회복지·간호직 전체 합격생 중 70% 혹은 80%가 자사 수강생인 것처럼 거짓 광고했다. 그 근거가 되는 정보는 작은 글씨에 배경색과 유사한 색을 사용하는 등 소비자가 인식하기 어렵게 은폐·축소 광고했다. 공정위는 '수험서 1위' '매출 1위' '수강생 수 1위' 등의 광고 문구도 문제 삼았다. 그 근거가 되는 정보를 소비자가 인식하기 어렵게 작은 글씨에 배경색과 유사한 색을 사용해 은폐했다는 지적을 받았다.공정위 관계자는 "합격률이나 순위는 소비자 구매 선택에 중요한 정보에 해당한다"면서 "거짓 광고를 하고 주요 정보를 은폐하면 소비자의 합리적인 구매 선택에 영향을 주고, 공정한 거래질서를 저해할 수 있다"고 말했다. 공정위가 경쟁이 치열한 온라인 강의 시장에서 무리한 광고 관행에 제동을 걸었다는 분석이 제기된다.하지은 기자 hazzys@hankyung.com

-
3
AI 스타트업 올거나이즈, LLM 에이전트 역량 평가 플랫폼 출시
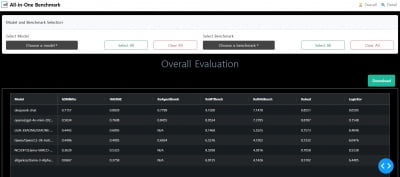
거대언어모델(LLM) 올인원 솔루션 기업 올거나이즈가 LLM의 에이전트 역량을 평가하는 ‘All-in-One Benchmark(올인원 벤치마크)’를 공개한다고 3일 밝혔다.올인원 벤치마크는 LLM의 에이전트 성능을 종합적으로 평가하는 플랫폼이다. 수요 기업은 이를 통해 에이전트 역할을 수행하기에 가장 적합한 LLM을 선택한다. LLM이 에이전트 역할을 수행하기 위해서는 도메인별 지식뿐 아니라 문제 해결을 위한 툴을 선택 및 활용할 수 있는 능력, 대화의 맥락 이해, 수집된 정보 활용 등 다양한 능력이 요구된다. 공개된 벤치마크를 활용해 LLM을 다각도로 분석하며, 평가 결과를 한눈에 볼 수 있도록 대시보드 형태로 제공한다.문제 해결을 위해 자율적으로 행동하는 에이전트의 중요성이 커지면서 지난해 공개한 ‘금융 전문 LLM 리더보드’에서 한 발 나아가 새로운 LLM 평가 플랫폼을 제시했다고 회사 측은 설명했다. 사용자는 플랫폼 내에서 올거나이즈의 자체 소형언어모델(sLLM)을 비롯한 ‘ChatGPT(챗지피티)’, ‘EXAONE(엑사원)’, ‘Qwen(큐원)’, ‘DeepSeek(딥시크)’ 등 12개의 LLM의 평가 결과를 확인할 수 있다. 에이전트 성능을 종합적으로 평가하는 데는 3가지 벤치마크가 활용된다.다양한 상황에서 스스로 외부 도구를 호출하는 ‘툴 콜링(tool calling)’ 능력을 평가하는 데는 ‘BFCL’를, 한국어 환경에서의 툴 콜링 능력 평가는 ‘FunctionChatBench’를 활용한다. ‘TauBench’라는 벤치마크를 통해서는 유통, 항공 등 실제 산업 현장의 다양한 상황에서 LLM의 문제 해결 능력을 평가한다.새로운 LLM의 성능도 쉽게 확인한다. 새로 나온 LLM 이름을 입력하면 플랫폼이