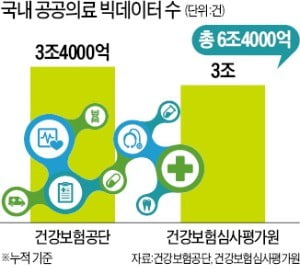
건강보험공단 건강보험심사평가원 등 공공기관에 축적된 공공 의료 빅데이터가 6조 건을 웃돌지만 무용지물 신세를 면치 못하고 있다. 세계적으로 양질의 의료정보로 평가받지만 정작 신약 개발 등에 제대로 활용되지 못하고 있어서다. 이 때문에 국내 바이오헬스케어 업체들이 인공지능(AI) 등을 활용한 신약 개발과 건강관리 서비스 등에서 뒤처질 수 있다는 우려가 나온다.
21일 건보공단과 심평원에 따르면 두 기관이 보유한 의료 빅데이터는 각각 3조4000억 건과 3조 건이다. 제약회사 등이 건보공단이나 심평원에서 열람할 수 있는 의료정보는 최대 120만 명의 진료 데이터로 제한되고 있다. 개인정보 보호를 위해 매년 건강보험으로 진료받은 환자의 3%가량만 뽑아 지역별 처방약, 질환 등의 비식별 의료정보를 공개하기 때문이다. 업계 관계자는 “국내 제약사들은 신약 개발 경험이 적어 자체적으로 모은 빅데이터가 턱없이 부족하다”며 “공공 의료 데이터를 상업적으로 사용하는 데 제약이 많다 보니 해외에서 데이터를 사서 쓰고 있다”고 했다.
유전체 빅데이터 확보도 막혀 있다. 소비자 의뢰 유전자검사(DTC)가 피부, 모발 등 건강 관련 12개 항목으로 제한돼 있어 기업이 질병 관련 유전체 데이터를 모을 수 없기 때문이다. 미국 영국 핀란드 등이 헬스케어산업 육성을 위해 유전체 빅데이터 구축에 열을 올리고 있는 것과는 대조적이다. 미국은 2022년까지 100만 명의 유전체 빅데이터를 확보하는 프로젝트를 가동 중이다.
의료 빅데이터 활용에 가장 큰 걸림돌은 시민단체와 정치권이다. 경제정의실천시민연합 등 시민단체들은 의료 개인정보 유출 우려가 있다며 민간의 공공 의료 빅데이터 활용을 반대하고 있다. 송승재 한국디지털헬스산업협회장은 “의료 데이터를 보는 편협한 시각을 버리고 개인정보를 보호하면서도 의료 빅데이터를 국민 건강에 이롭게 쓸 방법을 찾아야 한다”고 말했다.
< 바이오의약품 품질 검사 > 한미약품 평택 바이오플랜트에 근무하는 연구원들이 바이오의약품 품질검사를 하고 있다. 한미약품 등 국내 제약바이오업체들은 인공지능(AI) 등을 활용해 신약 개발에 나서고 있으나 의료 빅데이터 부족 등으로 애로를 겪고 있다. /평택=강은구 기자 egkang@hankyung.com익명 정보도 시민단체 '어깃장'…의료 데이터 고작 3% 공개
세계적인 경영컨설팅기업 맥킨지는 빅데이터 기술이 적용될 대표적인 분야로 보건의료를 꼽았다. 한국의 보건의료 빅데이터는 세계 최고 수준이라는 평가를 받는다. 의료 데이터를 전자화해 저장할 수 있는 프로그램인 전자의무기록(EMR) 도입률이 92%로, 세계에서 가장 높다. 서울 신촌세브란스병원에 있는 의료 데이터 규모만 10여 페타바이트(PB)에 달한다. 1PB는 700MB짜리 영화 150만 편을 저장할 수 있는 크기다.
건강보험심사평가원과 국민건강보험공단이 보유하고 있는 보건의료 빅데이터도 6조 건이 넘는다. 그러나 업계에서는 “의료 빅데이터의 잠재력은 무궁무진하지만 이를 제대로 활용할 여건이 안 된다”는 지적이 나온다.
보건의료 빅데이터 양 적고 분절돼
병원의 진료 데이터는 환자의 구체적인 치료 기록을 담고 있어 이를 활용하면 환자 특성을 고려한 정밀의료 및 헬스케어 서비스를 개발할 수 있다는 게 업계 주장이다. 그러나 기업은 이 데이터에 자유롭게 접근하기 힘들다. 생명윤리법에 따라 함께 연구할 의사를 찾고 병원 데이터로 무엇을 연구할지 계획한 뒤 각 의료기관의 임상시험심사위원회(IRB)에 승인을 받아야 한다.
심혈관질환 환자를 모니터링하는 서비스를 개발 중인 라인웍스는 3개 병원으로부터 관련 데이터를 확보하는 데만 6개월이 걸렸다. 회사 관계자는 “IRB에서 신청이 반려되면 계획을 수정하는 과정을 여러 번 거쳤다”며 “각 병원의 IRB마다 심사 기준이 달라 같은 연구도 어떤 곳은 되지만 다른 곳은 안 되기도 한다”고 말했다.
심평원과 건보공단의 공공 의료 빅데이터도 상업적 활용이 사실상 막혀 있다. 개인을 특정할 수 없게 비식별화한 만큼 개인정보보호법 등을 위반하지 않는 한 상업적으로 쓸 수 있지만 실제 기업 등에 제공되는 데이터는 매우 제한적이다. 심평원은 전체 데이터가 아니라 매년 국민의 3%가량을 무작위로 추출해 가공한 데이터를 제공한다. 데이터 양이 적을 뿐 아니라 데이터가 1년씩 분절돼 있어 장기 분석이 불가능하다. 건보공단은 자체 규정에 근거해 공단 내 분석센터에서 공익적 목적으로만 데이터 열람을 허용한다.
일각에서는 이 같은 조치가 개인정보 보호를 위해 필요하다고 하지만 업계는 아쉽다는 반응이다. 제약업계 관계자는 “온전한 데이터를 활용하면 약물 이상사례, 환자 수요, 약물 효과 등을 분석해 부가가치가 큰 자료를 얻을 수 있어 신약 개발 등에 유용하게 쓰일 것”이라고 했다.
유전자 데이터 미국의 1%도 안 돼
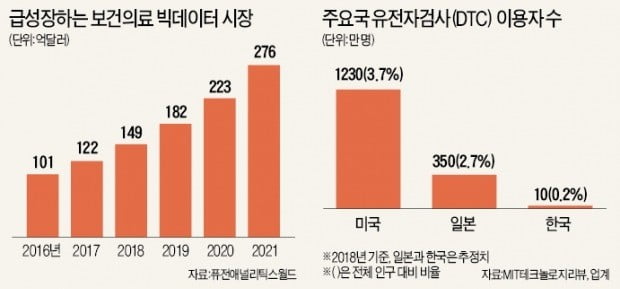
유전체 빅데이터 구축도 선진국에 비해 지지부진하다. 소비자 의뢰 유전자검사(DTC) 항목이 피부, 탈모 등 12개 항목 46개 유전자로 제한돼 있기 때문이다. DTC는 의료기관을 거치지 않고 소비자가 업체에 직접 유전체 분석을 의뢰하는 서비스다. 질병과 관련된 유전자 분석이 금지돼 있어 데이터의 질이 떨어질 뿐만 아니라 시장 수요도 크지 않다.
MIT테크놀로지리뷰에 따르면 미국의 지난해 DTC 이용자는 1230만 명, 일본은 350만 명이었다. 국내는 약 10만 명에 그치는 것으로 업계는 추산하고 있다. 마크로젠 관계자는 “미국, 영국, 핀란드 등은 정부가 나서 자국민의 유전체 빅데이터를 구축하고 있다”며 “한국에서는 질환 관련 유전체 데이터가 대부분 병원에 있어 활용하기 쉽지 않다”고 했다.
스탠다임, 신테카바이오, 테라젠이텍스 등 신약 개발 비용과 시간을 절감하기 위해 인공지능(AI)을 활용하는 업체가 늘고 있지만 AI를 학습시킬 빅데이터를 확보하기 힘들다는 목소리가 높다. 업계 관계자는 “신약 개발 성공률을 높이려면 화합물과 단백질의 분자 구조 데이터 등 공개 데이터만으로는 안 된다”며 “유전체 데이터는 기술적으로 식별이 어려운 만큼 활용 폭을 넓혀야 한다”고 했다.
“의료데이터 보는 시각 바꿔야”
공공의료 빅데이터 공개가 제대로 이뤄지지 않는 데는 2016년 정부가 발간한 ‘개인정보 비식별 조치 가이드라인’이 불명확하다는 점도 꼽힌다. 박대웅 한국보건산업진흥원 미래산업기획팀장은 “가이드라인의 비식별화 규정이 모호할 뿐 아니라 상위법으로 가이드라인에 법적 권한을 위임하지 않았다”며 “기업이 가이드라인에 따라 비식별화해도 개인정보보호법 등에 위배될 수 있다”고 했다.
경제정의실천시민연합 등 시민단체는 비식별 처리된 의료 개인정보의 상업 용도 활용에 반대하고 있다. 과학기술정보통신부가 시범사업을 추진 중인 마이데이터사업이 대표적이다. 환자가 블록체인 기반 플랫폼을 통해 의료데이터를 스스로 관리할 수 있게 하는 것이다. 하지만 이 사업에 삼성화재가 참여한다는 이유로 시민단체와 정치권에서는 “개인정보가 유출돼 상업적으로 활용될 수 있다”고 주장했다.
전문가들은 의료 빅데이터를 보는 시각부터 바꿔야 한다고 강조했다. 조용현 라인웍스 대표는 “영국, 핀란드 등도 한국처럼 개인정보 유출을 민감하게 여기고 강력히 통제한다”면서도 “선진국에서는 의료 빅데이터를 국민 건강에 유익하게 활용하자는 방향으로 사회적 논의가 이뤄지고 있는데 국내에서는 소모적인 갈등만 반복된다”고 했다.