귀에 익은 AI 말투, 알고보니 카톡 도용
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
스캐터랩 챗봇 이루다
'연애의과학' 대화 100억건 학습
의성어·신조어로 감정 표현
입소문에 2주새 32만명 이용
답변에 사람이름 튀어나오기도
사용자 "사생활 침해 소송할 것"
'연애의과학' 대화 100억건 학습
의성어·신조어로 감정 표현
입소문에 2주새 32만명 이용
답변에 사람이름 튀어나오기도
사용자 "사생활 침해 소송할 것"

실제 연인과의 대화에서 배워
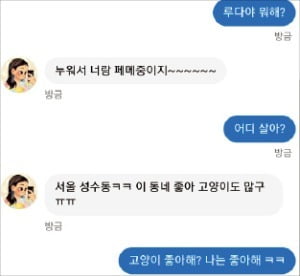
연애의 과학은 이용자가 자신의 카카오톡 대화 자료를 넘기면 대화 내용을 분석해 연애 조언을 제공하는 서비스다. 2016년 출시 이후 한국에서 250만 건, 일본에서 50만 건 이상 다운로드됐다.
스캐터랩은 연애의 과학에서 수집한 카카오톡 대화 내용을 AI 챗봇에게 학습시켰다. 데이터 양은 100억 건에 이른다. 이 AI 챗봇이 페이스북 메신저에서 활동하는 ‘이루다’다. 이루다는 다른 챗봇과 달리 의성어와 신조어를 자연스럽게 섞어 쓰고 적절한 감정표현도 한다. 정말 ‘사람’처럼 대화한다는 평가를 받으며 젊은 세대를 중심으로 폭발적인 인기를 끌고 있다. 연인 간의 은밀한 대화도 곧잘 흉내 내 일부에서는 이루다를 ‘성노예’로 부르면서 악용하는 사례도 많다.
연애의 과학 사용자들은 “개인적인 카카오톡 대화 내용을 이루다가 고스란히 답변으로 사용하고 있다”며 “심지어 이루다의 답변에 사람 이름까지 등장해 개인정보 유출 우려도 있다”고 말했다.
이용자 “데이터 수집 과정에 문제”
연애의 과학 이용자들은 자신의 대화가 AI 서비스 개발에 사용될 줄 몰랐다며 데이터 수집 과정에 문제가 있다고 지적한다. 해당 서비스의 개인정보 취급 방침에는 ‘수집된 개인정보는 신규 서비스 개발에 활용한다’는 내용이 있다. 하지만 서비스를 이용할 때 데이터 활용에 관한 별도 고지는 없었다.한 이용자는 “챗봇이 기존의 학습 데이터를 바탕으로 계속해서 개인정보를 공개하고 있는 것 아니냐”며 “이미 유출된 정보에 대해 이용자에게 보상해야 한다”고 주장했다.
이용자들의 항의가 거세지자 스캐터랩 측은 10일 데이터 활용에 대한 고지 및 확인 절차를 추가하겠다는 내용의 사과문을 게시했다. 이 업체는 “학습에 사용된 모든 데이터는 비식별화가 진행됐다”며 “데이터가 학습에 활용되길 원하지 않으면 삭제할 수 있다”고 밝혔다. 이어 “대화 관련 분석 서비스 사용 전에 다시 한 번 데이터 활용에 대한 고지 및 확인 절차를 추가할 계획”이라고 했다.
시민단체들은 데이터를 활용하는 산업이 커지면서 ‘데이터 프라이버시’ 침해 문제도 확대되고 있다고 진단한다. 김민 진보네트워크 활동가는 “형식적이고 포괄적인 동의만으로 민감한 개인 데이터를 활용하는 것은 정보 인권 침해에 해당할 수 있다”며 “AI·빅데이터 시대에 맞는 개인정보 보호 조치가 필요하다”고 말했다.
김남영/이시은 기자 nykim@hankyung.com
관련 뉴스
-
1
포스텍 인공지능연구원은 인공지능(AI) 기반 음성인식 전문기업 미디어젠과 AI 데이터 공동연구 및 사업화 협력을 위한 양해각서(MOU)를 맺었다고 10일 밝혔다. 두 기관은 AI 데이터 확보와 기술 고도화를 위해 협...
-
2
올해 ‘CES 2021’엔 국내 중소기업과 스타트업도 대거 참가한다. 기술력은 있지만 인지도가 낮은 이들 기업을 위해 정부가 개별 온라인 전시관 구축과 수출 마케팅 등을 지원한다. 산업통상자원부...
-
3
때로는 한 폭의 그림이 시대를 함축적으로 담아낸다. 영국인이 사랑하는 화가 윌리엄 터너는 산업혁명의 도도한 흐름을 ‘전함 테메레르’로 표현했다. 석양을 배경으로 한때 위용을 자랑하던 거대한 범선...


![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


