
정부 '대화 데이터 수집' 절차 보니…"카톡 상대방 동의도 구해야"
공공기관은 저작권 계약 체결하고 보상도 지급
개인정보위 조사 주목…"개인정보보호법 위반 가능성에 무게"

인공지능(AI) 챗봇 '이루다'가 서비스를 잠정 중단했지만 이루다 개발에 쓰인 카카오톡 대화 데이터가 위법하게 수집됐다는 문제 제기가 계속되고 있다.
AI 전문가들은 "스캐터랩이 개인정보 및 저작권 동의를 꼼꼼히 받지 않은 책임이 있어 보인다"고 지적한다.
개인정보보호위원회 조사 결과에 따라 스캐터랩이 법적 책임을 질 가능성도 대두되고 있다.
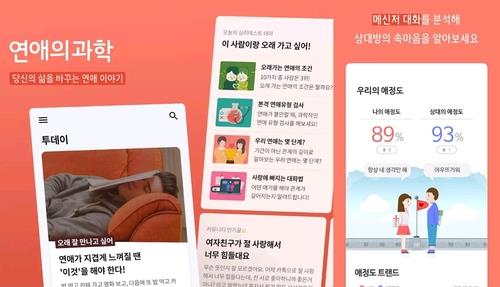
13일 IT업계에 따르면, 스캐터랩은 연애 분석 앱 '연애의 과학'에서 수집한 연인들 대화 데이터 약 100억건으로 AI 챗봇 이루다를 만들었다.
그런데 이 과정에서 스캐터랩은 연애의 과학 이용자들에게 '개인정보가 신규 서비스 개발에 활용될 수 있다'는 정도만 고지해 설명이 부족했다는 지적을 받고 있다.
AI 전문가들은 최근 공공기관이 시행한 대화 데이터 수집 사업과 스캐터랩 사례를 비교해보면 스캐터랩의 개인정보 취급이 어떤 점에서 부족했는지 알 수 있다고 입을 모은다.
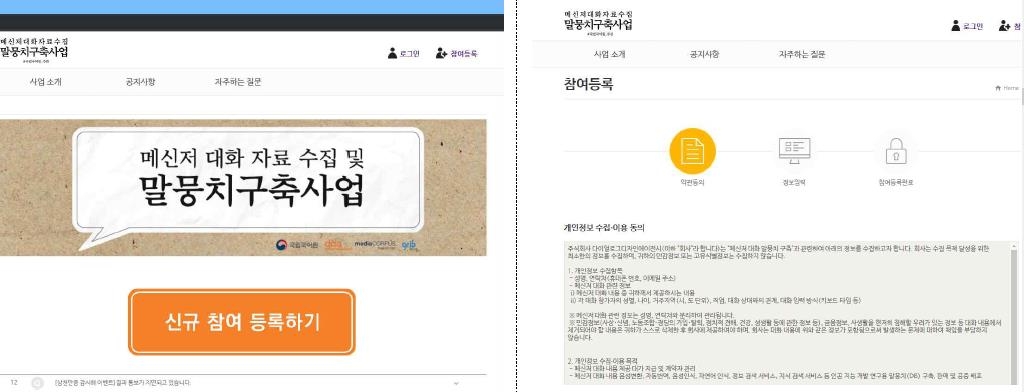
최근의 공공기관 사례는 과학기술정보통신부와 한국정보화진흥원(NIA)이 지난해 9월 시작한 'AI 학습용 데이터 구축 2차 사업'이다.
사업 주관 기관인 NIA는 카카오톡 이용자를 대상으로 'AI 학습용 한국어 대화 데이터 수집'을 하고 있는데, 이를 위해 이 기관은 44쪽에 달하는 상세한 매뉴얼을 제작해 참여자들에게 제공했다.
신청 절차를 보면 이 사업 참여자는 개인정보 처리 동의서, 저작권 이용 허락 계약서, 크라우드 워커(Crowd Worker) 용역 계약서를 써야 한다.
NIA는 데이터를 제출하는 신청자뿐 아니라, 신청자와 대화를 나누는 카톡 대상도 모두 신청서 및 저작권 계약서를 쓰도록 했다.
전문가들은 스캐터랩이 연애의 과학 이용자들에게서 카톡 대화를 수집하면서 대화 상대방인 제3자에게는 아무런 동의를 얻지 않은 점이 문제라고 지적한다.
스캐터랩이 카톡 대화를 신규 서비스에 쓰려고 했으면 최소한 NIA처럼 제3자 개인정보 활용 동의만큼은 얻었어야 한다는 것이다.

2019년 문화체육관광부와 국립국어원이 벌인 '메신저 대화 자료 수집 및 말뭉치 구축 사업'도 같은 절차를 거쳤다.
국립국어원 역시 NIA처럼 신청자 외 대화방 참여자들에게 개인정보 제공 이용 동의를 받았고, 저작권 이용 허락 계약도 체결했다.
저작권 계약에는 계약 종료일 및 자동 갱신 단위, 저작물의 제공·배포 및 보존·복제·변형·응용 등의 권한을 넘긴다는 구체적인 내용이 적시됐다.
이 사업 위탁업체는 최종 보고서에 "대화를 수집하려면 대화 참여자의 개인정보까지 수집해야 하는데, 이를 위해서는 개인정보 이용 동의가 꼭 필요하다"며 "자료를 활용하려면 저작권 이용 허락도 필요하다"고 적었다.
업체 측은 "메신저 대화처럼 사적이고 일상적인 대화가 저작권 이용 허락 대상인지는 현재 명확한 법적 기준이 없다"면서도 "본 사업에서는 메신저 대화도 어문 저작물에 준하는 것으로 간주해 대화 제공자 전원과 저작권 이용 허락 계약을 체결했다"고 부연 설명했다.
추후 문제가 없도록 현행 법·제도 이상으로 철저히 절차를 밟았다는 것이다.
NIA와 국립국어원은 데이터 제공자들에게 보상도 했다.
NIA는 대화 조각 1건당 700원(세전)의 보상을 지급하고 있다.
1명당 최대 1만건의 대화 조각을 업로드할 수 있으므로 700만원까지 받을 수 있다.
국립국어원은 대화 길이에 따라 모바일 상품권을 최소 5천원, 최대 5만원까지 지급했다.
스캐터랩은 연애의 과학 이용자들의 카톡 대화를 수집해 신규 서비스에 활용하면서 보상하지 않았다.
오히려 연애의 과학 서비스는 건당 2천∼5천원 정도로 유료였다.
물론 NIA와 국립국어원의 데이터 수집 사업은 자발적인 참여자들이 익명화 작업까지 손수 거친다는 점에서 보상 수준을 스캐터랩과 동등하게 비교하기는 어렵다.
그러나 AI 스타트업 한 관계자는 "데이터가 '쌀이자 원유'라는 시대 아니냐. 카톡 대화처럼 민감한 데이터를 수집하려면 보상을 하는 게 당연하다"며 "동의조차 제대로 받지 않았다니 이해하기 어렵다"고 의견을 냈다.
개인정보 침해 사건을 담당하는 정부 부처 개인정보보호위원회는 한국인터넷진흥원(KISA)과 함께 스캐터랩 조사에 착수했다.
개인정보위 관계자는 "개인정보보호법 위반 가능성에 무게를 두고 있다"고 말했다.
법조계에서는 개보위 조사 결과에 따라 스캐터랩이 상당한 위자료 보상 책임을 질 수도 있다는 관측이 나온다.
개인정보 전문가인 김보라미 변호사(법률사무소 디케)는 "스캐터랩은 개인정보를 마케팅·광고에 쓰겠다는 동의까지 포괄적으로 받은 점, 제3자 개인정보 이용 동의를 안 받은 점 등이 위법 소지가 있어 보인다"고 말했다.
/연합뉴스
공공기관은 저작권 계약 체결하고 보상도 지급
개인정보위 조사 주목…"개인정보보호법 위반 가능성에 무게"
AI 전문가들은 "스캐터랩이 개인정보 및 저작권 동의를 꼼꼼히 받지 않은 책임이 있어 보인다"고 지적한다.
개인정보보호위원회 조사 결과에 따라 스캐터랩이 법적 책임을 질 가능성도 대두되고 있다.
13일 IT업계에 따르면, 스캐터랩은 연애 분석 앱 '연애의 과학'에서 수집한 연인들 대화 데이터 약 100억건으로 AI 챗봇 이루다를 만들었다.
그런데 이 과정에서 스캐터랩은 연애의 과학 이용자들에게 '개인정보가 신규 서비스 개발에 활용될 수 있다'는 정도만 고지해 설명이 부족했다는 지적을 받고 있다.
AI 전문가들은 최근 공공기관이 시행한 대화 데이터 수집 사업과 스캐터랩 사례를 비교해보면 스캐터랩의 개인정보 취급이 어떤 점에서 부족했는지 알 수 있다고 입을 모은다.
사업 주관 기관인 NIA는 카카오톡 이용자를 대상으로 'AI 학습용 한국어 대화 데이터 수집'을 하고 있는데, 이를 위해 이 기관은 44쪽에 달하는 상세한 매뉴얼을 제작해 참여자들에게 제공했다.
신청 절차를 보면 이 사업 참여자는 개인정보 처리 동의서, 저작권 이용 허락 계약서, 크라우드 워커(Crowd Worker) 용역 계약서를 써야 한다.
NIA는 데이터를 제출하는 신청자뿐 아니라, 신청자와 대화를 나누는 카톡 대상도 모두 신청서 및 저작권 계약서를 쓰도록 했다.
전문가들은 스캐터랩이 연애의 과학 이용자들에게서 카톡 대화를 수집하면서 대화 상대방인 제3자에게는 아무런 동의를 얻지 않은 점이 문제라고 지적한다.
스캐터랩이 카톡 대화를 신규 서비스에 쓰려고 했으면 최소한 NIA처럼 제3자 개인정보 활용 동의만큼은 얻었어야 한다는 것이다.
국립국어원 역시 NIA처럼 신청자 외 대화방 참여자들에게 개인정보 제공 이용 동의를 받았고, 저작권 이용 허락 계약도 체결했다.
저작권 계약에는 계약 종료일 및 자동 갱신 단위, 저작물의 제공·배포 및 보존·복제·변형·응용 등의 권한을 넘긴다는 구체적인 내용이 적시됐다.
이 사업 위탁업체는 최종 보고서에 "대화를 수집하려면 대화 참여자의 개인정보까지 수집해야 하는데, 이를 위해서는 개인정보 이용 동의가 꼭 필요하다"며 "자료를 활용하려면 저작권 이용 허락도 필요하다"고 적었다.
업체 측은 "메신저 대화처럼 사적이고 일상적인 대화가 저작권 이용 허락 대상인지는 현재 명확한 법적 기준이 없다"면서도 "본 사업에서는 메신저 대화도 어문 저작물에 준하는 것으로 간주해 대화 제공자 전원과 저작권 이용 허락 계약을 체결했다"고 부연 설명했다.
추후 문제가 없도록 현행 법·제도 이상으로 철저히 절차를 밟았다는 것이다.
NIA는 대화 조각 1건당 700원(세전)의 보상을 지급하고 있다.
1명당 최대 1만건의 대화 조각을 업로드할 수 있으므로 700만원까지 받을 수 있다.
국립국어원은 대화 길이에 따라 모바일 상품권을 최소 5천원, 최대 5만원까지 지급했다.
스캐터랩은 연애의 과학 이용자들의 카톡 대화를 수집해 신규 서비스에 활용하면서 보상하지 않았다.
오히려 연애의 과학 서비스는 건당 2천∼5천원 정도로 유료였다.
물론 NIA와 국립국어원의 데이터 수집 사업은 자발적인 참여자들이 익명화 작업까지 손수 거친다는 점에서 보상 수준을 스캐터랩과 동등하게 비교하기는 어렵다.
그러나 AI 스타트업 한 관계자는 "데이터가 '쌀이자 원유'라는 시대 아니냐. 카톡 대화처럼 민감한 데이터를 수집하려면 보상을 하는 게 당연하다"며 "동의조차 제대로 받지 않았다니 이해하기 어렵다"고 의견을 냈다.
개인정보 침해 사건을 담당하는 정부 부처 개인정보보호위원회는 한국인터넷진흥원(KISA)과 함께 스캐터랩 조사에 착수했다.
개인정보위 관계자는 "개인정보보호법 위반 가능성에 무게를 두고 있다"고 말했다.
법조계에서는 개보위 조사 결과에 따라 스캐터랩이 상당한 위자료 보상 책임을 질 수도 있다는 관측이 나온다.
개인정보 전문가인 김보라미 변호사(법률사무소 디케)는 "스캐터랩은 개인정보를 마케팅·광고에 쓰겠다는 동의까지 포괄적으로 받은 점, 제3자 개인정보 이용 동의를 안 받은 점 등이 위법 소지가 있어 보인다"고 말했다.
/연합뉴스
![[단독] 스캐터랩이 수집한 카톡 대화…'이루다'에만 쓰지 않았다](https://img.hankyung.com/photo/202101/01.24985445.3.jpg)






