AI가 "왜?"라는 질문에 답을 하려면
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
김진형 중앙대 석좌교수겸 KAIST 명예교수(한경AI경제연구소 자문위원장)

몸이 아파서 AI의사를 만났더니 몇 가지 물어보고 약 처방을 한다. 헌데 내가 무슨 병에 걸렸고 왜 이 비싼 약을 먹어야 되는지 AI의사가 설명을 못 한다. 환자는 얼마나 불안할까? 다시는 이런 AI의사를 찾지 않을 것 같다. 그러나 상황은 그렇게 단순하지 않다. 의사결정 과정을 설명하지 못하는 AI의사의 완치 확률이 95%이고, 인간의사는 설명을 잘 하지만 완치 확률이 75% 라면 당신은 어느 의사를 선택할 것인가? AI의 능력이 점점 더 강력해지면서 설명을 못해도 성능이 우수한 AI를 선호하는 사례가 더 많아질 것이다. 중요한 결정을 AI가 대신하는데도 인간은 그 과정을 이해하지 못한다면 세상은 어떻게 될까? ‘이해하는 존재’라는 인간의 특성은 유지될 수 있을까?
개인의 기호에 맞는 영화를 추천하는 정도야 그 과정을 몰라도 심각하지 않겠지만, 채용 면접이나 융자 신청에서 거부당했다면 왜 거부당했는지 알고 싶어 할 것이다. 또 생명을 다루는 의학적 판단은 어떤 과정을 거쳐서 결과를 도출했는지 꼭 알고 싶다. 기계학습형 AI시스템은 데이터에 포함되어 있던 편견이 그대로 반영되어 불공정한 판단을 한다는 것은 이미 잘 알려져 있다. 내가 불공정한 대접을 받은 것이 아닌가? 사회는 사악해서 이익을 위하여 소비자에게 해를 끼치는 알고리즘을 장착한 제품을 종종 접한다. 이런 상황에서 알고리즘의 투명성은 매우 중요한 요구 사항이다. 유럽연합에서는 알고리즘이 판단하는 경우 당사자는 설명을 요구할 권한이 있다고 선언했다.
실용적인 AI를 만들려는 최초의 노력이 있었던 1970년대부터 의사결정 과정을 투명하게 밝히는 방법론의 연구는 AI 연구의 중요한 테마였다. 전문 지식을 이용하여 의사결정을 자동화하는 전문가 시스템에서는 판단에 사용된 규칙을 자연어 형태로 보여주었다. 이런 시스템들은 의사결정 과정을 투명하게 보여줄 수 있어서 각광을 받았으나 복잡한 의사결정 문제에서는 요구되는 성능을 내기가 힘들어 요즘은 잘 사용되지 않는다.
최근 데이터를 학습하여 알고리즘을 만드는 딥러닝 방법론이 복잡한 문제에서도 좋은 성능을 보여서 AI의 붐을 다시 일으켰다. 딥러닝은 입력과 출력 간의 연관관계를 데이터로부터 학습한다. 즉 연관관계를 통계적으로 추론하는 기법이다. 추론의 중간 단계에서 무엇을 계산할지, 즉 어떤 변수를 사용할 것인가를 스스로 알아서 결정한다. 딥러닝은 알고리즘 개발과정을 자동화하는 것으로서 큰 가치가 있다.
그러나 딥러닝 기법은 높은 성능을 보이지만 안타깝게도 의사결정의 과정을 인간의 언어로 설명을 하지 못한다. 변수를 설계하는 사람들조차 변수가 어떻게 결합되고, 어떤 계산을 하는지 그 계산과정이 복잡하여 이해할 수 없다. 내부 계산 과정을 숫자로 보여줄 수는 있지만 사람이 이해할 수 없다. 그런 의미에서 신경망은 블랙박스 시스템이다. 훈련에 사용한 데이터집합에 결함이 있을 수도 있고, 데이터가 과적합 되어 간단한 것도 일반화를 못할 수 있지만 확인할 길이 없다. 검증 데이터집합을 통해서 성능을 확인하는 것이 고작이다. 이런 이유로 딥러닝으로 학습한 자율주행 알고리즘이 종종 사고를 내고, 비윤리적인 행동하는 챗봇이 나타나는 것이다.
현장에서는 기계학습된 알고리즘의 설명 가능성을 높이기 위하여 두 가지 접근법을 사용한다. 첫째는 설명이 가능할 정도로 모델을 단순화하는 것이다. 전통적인 선형회귀법이나 의사결정 트리 기법은 단순해서 설명이 가능하다. 그러나 성능이 떨어지는 것은 피할 수 없다. 해석성을 위해서 정확성을 희생한다는 것은 바람직하지 않다. 둘째는 별도의 설명 모델을 만드는 것이다. 이런 접근법도 문제가 있다. 의사결정 모델과 설명모델이 일치하지 않을 가능성이 항상 존재한다. 완전히 다른 모델을 사용하여 설명을 시도하거나 다른 통계를 사용할 가능성이 있다.
자연스러운 설명을 하기 위해서는 통계적 연관관계 그 이상의 것이 요구된다. 사람들은 의사결정 과정을 설명하기 위하여 나름대로 모델을 사용한다. 즉 인과관계, 계층관계 등의 모델을 사용하여 설명하곤 하는데 딥러닝은 그런 것들을 배우지도 못하고 사용하지도 못한다. 의사결정 과정에 대한 대화에서는 인과관계가 무엇보다도 중요하다. 왜 이렇게 결정했는지가 핵심일 수밖에 없다. 의사와 환자의 대화는 왜 그 병이라고 진단했는지, 왜 그 약을 먹어야 하는지가 핵심이다.
하나님과 아담과에 대화도 ‘왜?’의 연속이다. “너는 왜 그 사과를 먹었니?”, “당신이 지정해 준 이브가 먹으라 해서요”, ”이브야, 너는 왜 사과를 먹자고 했니?”, “뱀이 사과를 먹으면 눈이 밝아진다고 해서요”, 등등 이런 식의 인과관계에 관한 대화가 인간 대화의 대부분이다. 계몽시대 이후 인간의 이성은 과학을 기반으로 했고, 과학은 인과관계의 탐구다. 사과는 왜 떨어지는지? 일년은 왜 365일인지? 등등.
인과관계는 연관관계에 추가하여 원인과 결과의 지식이 필요하다. 오동잎이 떨어짐과 가을이 온 것이 연관관계가 있는 것은 알지만, 가을이 와서 오동잎이 떨어진 것인지, 오동잎이 떨어져서 가을이 온 것인지는 신경망은 알지 못한다. 아니면 두 사건의 공통 원인이 있을 수도 있다. ‘왜?’를 설명하려면 원인과 결과에 관한 모델이 필요하다. 또 인과관계를 사용해야 ‘만약 ~했다면’과 같은 가설상황에 대한 추론이 가능하다. 사람은 개똥철학 일지라도 나름대로 철학, 즉 이론과 모델을 갖고 결정하고 설명한다.
데이터로부터 인과관계를 배우는 AI기술은 아직 초보 단계에 머물러 있다. 인간은 오랜 과학적 연구를 통해서 인과관계 모델을 세우고 검증해 왔다. 설명 가능한 AI를 위해서는 인간이 쌓아온 지식을 이용하는 것이 필요하다. 즉 데이터 기반 방법론과 모델 기반의 방법론의 통합적 접근이 필요하다.
AI가 사회, 윤리, 법률 등의 요구사항을 충족하려면 설명 가능성은 선택적이 아니라 필수적인 기능이다. 이를 통하여 우리는 AI을 신뢰할 수 있는 동반자로 여길 것이다. 전지전능한 것처럼 알려져 있는 AI가 왜 자신이 하는 일에 대해서는 설명을 할 수 없을까? 아이러니가 아닐 수 없다. 그러나 현재의 AI가 어떻게 의사결정을 하고 어떻게 문제를 풀고자 하는 것을 알게 되면 고개를 끄덕일 것이다. 자신이 하는 일이 무엇인가를 잘 알고 인간에게 설명하는 AI의 출현은 좀 더 기다려야 할 것 같다. jkim@KAIST.edu
관련 뉴스
-
1
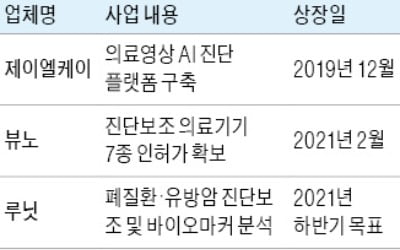
제이엘케이, 뷰노, 루닛 등 인공지능(AI)기반 영상 의료기 업체들이 앞다퉈 해외시장 문을 두드리고 있다. 회사의 덩치를 키우는 동시에 수익성도 끌어올리기 위해선 하루빨리 세계 무대에 데뷔해야 한다고 판단했기 때문이...
-
2
해양 기상 관측 부이(해상 부이)는 기상청이 해상에서 태풍 경로를 예측하거나 해운사들이 최적의 컨테이너선 항로를 설계할 때 이용하는 필수 장비다. 바다에 떠서 파도의 세기, 풍속, 수온, 습도, 조류, 기압 등을 위...

-
3
지난 1월 비대면으로 열린 청와대 신년 기자간담회에는 시스코의 협업 솔루션 웹엑스가 사용됐다. 지난해 신종 코로나바이러스 감염증(코로나19)으로 화상회의가 많아지면서 마이크로소프트 팀즈, 줌, 구글 미트 등이 주목받...


![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


