5도 사투리 음성·10개 암 영상…AI 학습용데이터 170종 풀린다
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트

과학기술정보통신부와 한국지능정보사회진흥원은 AI 학습용 데이터 170종, 4억8000만건을 'AI 허브' 홈페이지를 통해 18일부터 개방한다고 17일 밝혔다.
"산업계 '데이터 갈증' 풀어줄 것"
AI 학습용 데이터는 영상, 문서, 음성 등을 AI로 학습할 수 있는 형태로 가공(데이터 라벨링)한 것을 말한다. 산업계에선 "AI 서비스 개발에 필수인 빅데이터 구축이 쉽지 않다"는 의견이 많았다. 정부는 이에 2017년부터 AI 학습용 데이터를 구축해 개방하는 사업을 벌여왔다. 이른바 '데이터 댐' 사업이다. 2017~2019년에는 21종, 4650만건의 데이터를 개방·구축했다.작년엔 종 기준으로 2017~2019년의 8배, 건수는 10배 등 데이터 구축 양을 대폭 늘렸다. 정부는 올 상반기 데이터의 품질을 검증한 뒤 이번에 공개를 결정했다.
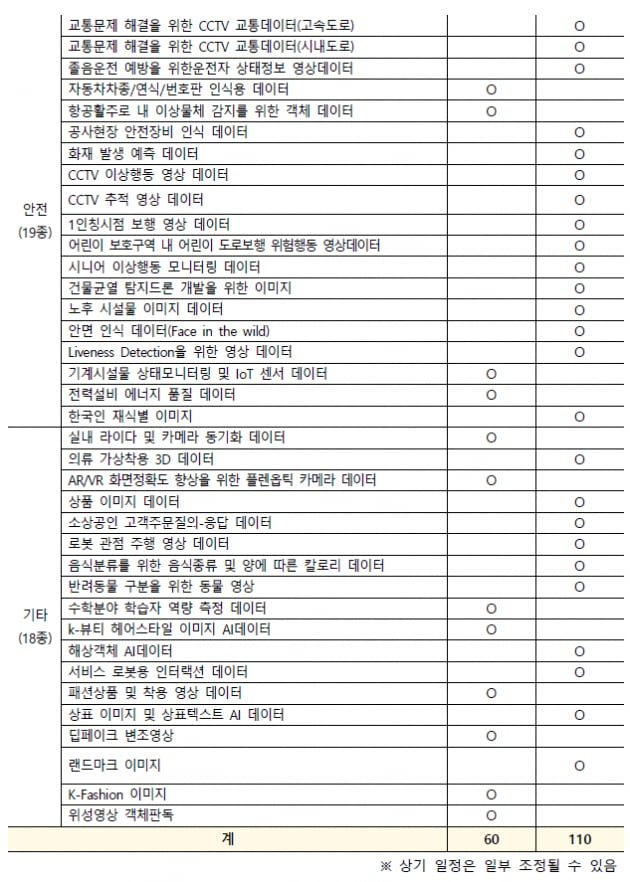
개방 데이터는 분야별로 △음성·자연어 39종 △헬스케어 32종 △자율주행 21종 △안전 19종 △비전 15종 △농축수산 14종 △국토환경 12종 △기타 18종 등이다.
음성·자연어에선 △경상·전라·강원·충청·제주도 등 방언 발화 데이터 5종 △한국어-외국어(영어, 중국어, 일본어) 번역 말뭉치 3종 △일반·노인·소아 등 자유대화 3종 등 데이터가 개방된다.
헬스케어는 △위·대장·폐·신장·간암 등 암 의료영상 데이터 10종 △치매 의료영상 데이터 △피트니스 자세 이미지 등이 있다. 자율주행 분야에선 △도로장애물·표면 영상 2종 △차선·횡단보도 영상 2종 △주차 장애물 등 데이터가 수집됐다.
이밖에 개방 데이터엔 △스포츠 동작 영상 △어류 행동 영상 △CCTV 이상행동 영상 등도 포함됐다.
데이터 건수가 가장 많은 종은 '수질 측정 및 오염원'으로 총 1억4000건이었다. 한국어 SNS 데이터(3200만건), 자율주행 드론 영상(1600만건) 등도 많았다.
18일에 한국어-외국어 번역 말뭉치 등 60종을 공개하고, 21~30일에 나머지 110종이 풀린다. 누구나 AI 허브에서 관심 있는 데이터를 다운 받아 AI 분석 등 사업에 활용할 수 있다.
양기성 과기부 데이터진흥과장은 "민간에서 대규모로 구축하기 어려우면서 산업 파급 효과가 클 것으로 예상되는 분야야 위주로 데이터를 구축했다"고 말했다. 이어 "빅데이터를 활용한 다양한 AI 서비스 개발이 촉진될 것으로 기대한다"고 했다.
일례로 방언 데이터는 사투리를 잘 인식하지 못했던 음성 기반 AI 서비스의 문제를 상당 부분 해결해줄 것이라는 게 정부 예상이다. 민간 기업에게 방언 데이터가 현장에서 활용도가 높을지 검토를 받은 결과 "기존 음성 인식 AI 서비스 인식률이 12% 향상됐다"는 평가를 받기도 했다. 자율주행 데이터는 특수 차선, 장애물, 포트홀 등 다양한 데이터가 포함돼 자율주행차 개발을 촉진할 것으로 기대된다.
"데이터 양만큼 품질이 좋냐가 관건"
과기부는 기업에서 실제 쓸 만한 데이터 구축을 위해 AI·데이터 전문기업, 주요 대학·병원 등 674개 기관과 함께 데이터 댐 사업을 진행했다. 정보통신기술협회(TTA)를 중심으로 데이터 품질 검증 절차를 거쳤다. 데이터 개방에 앞서 올 5~6월 네이버, 삼성전자, LG, KAIST, AI 스타트업 등 20여개 기업·기관으로부터 데이터 활용성 검토도 받았다.다만 음성·자연어, 영상 분야의 상당수 데이터는 실제 상황이 아닌 '시나리오' 기반으로 생성된 점은 아쉬운 부분으로 지적된다. 가령 자연대화 음성의 경우 실제 대화를 녹취한 것이 아니라 배우를 기용해 미리 정해진 시나리오대로 읽는 방식으로 데이터를 만들었다. 개인정보 침해 우려 때문이다. 정부는 실제 상황에 가깝게 시나리오를 설정했다고 하지만, 인위적으로 만든 데이터는 실제보다 품질이 떨어질 수밖에 없다. 시나리오 기반 생성 데이터는 총 38종이다.
워낙 많은 데이터를 만들다보니 그 안에 사회·윤리적으로 문제가 될 만한 데이터나 일반에 노출되면 안되는 민감 정보가 섞여있을 가능성도 있다. 과기부 관계자도 "데이터 검증을 꼼꼼히 했지만 문제 데이터가 절대 안 나온다고 장담할 수는 없다"고 했다. 이어 "데이터 개방 이후 9월말까지 '데이터 집중 개선 기간'을 운영해 문제가 될 만한 데이터가 신고되면 수정 작업을 거칠 예정"이라고 밝혔다. 다만 이렇게 해도 문제 데이터로 이미 AI를 학습시킨 기업은 분석 결과를 폐기해야 하는 경우가 생길 수 있다.
민간 AI 기업의 사업을 침해할 소지도 있다. 현재 크라우드웍스, 슈퍼브에이아이 등 스타트업은 AI 학습용 데이터를 만들어 판매하는 사업을 하고 있고 있기 때문이다. 박민우 크라우드웍스 대표는 "정부 데이터 댐 사업은 민간이 구축하기 어렵고 공공성이 있는 데이터 위주로 추진해야 부작용이 없을 것"이라고 말했다. 정부는 올해도 190종의 AI 학습용 데이터를 구축할 예정이다.
서민준 기자



-
1
정부는 일본 자위대가 홍보 영상을 통해 독도를 다케시마로 표기한 것과 관련해 항의의 뜻을 전달했다고 밝혔다.11일 외교부의 한 당국자는 "외교채널로 일본 측에 유감과 항의의 뜻을 분명하게 전달했다"며"우리 고유 영토...

-
2
리뷰 분석, 자동 댓글까지…전통시장도 AI로 고객관리한다
AI 기반 고객관리 솔루션을 제공하는 스타트업 르몽이 부산 구포시장 상인회와 ‘부산 구포시장 소상공인 활성화를 위한 AI 서비스 적용 업무협약(MOU)’을 체결했다고 7일 밝혔다. 르몽...
-
3
또 딥시크 쇼크?…부동산 구입 계획까지 세워주는 중국산 AI
중국의 인공지능(AI) 스타트업 딥시크가 일으킨 중국발 AI 돌풍이 이어지고 있다. 중국에서 AI 모델이 경쟁적으로 출시되는 가운데 한 스타트업이 선보인 AI 에이전트에 관심이 쏠리고 있다...


![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


