가비지 인, 가비지 아웃…"데이터가 AI의 전부였네"
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
'코알못' 기자의 AICE 도전기 (2)
가장 먼저 해야 할 일은 데이터의 전체적인 모습을 파악하는 것이다. 무엇에 관한 데이터인지, 이를 통해 어떤 사실을 알고 싶은지를 정리하는 게 첫 번째다. 데이터는 크게 피처(feature)와 레이블(label)로 구분된다. 피처를 x, 레이블을 y라고 부르기도 한다. 피처를 활용해 레이블을 예측하는 게 AI 모델의 최종적인 목표다. 예측에 앞서 데이터를 분석하고 유용한 피처와 필요 없는 피처를 선별하는 과정을 ‘탐색적 데이터 분석(EDA: exploratory data analysis)’이라고 부른다.
가령 공유 자전거 업체가 과거 기록을 기반으로 향후 자전거 수요량을 예측하려고 한다. 대여 날짜와 시간, 온도, 습도, 풍속 등은 피처, 대여 수량은 레이블이다. 분석하지 않아도 직관적으로 알 수 있는 사실이 있다. 눈, 비가 오면 대여량이 줄어든다거나 출·퇴근 시간에 대여량이 더 많을 것이라고 생각할 수 있다.
데이터 분석과 시각화 도구를 통해 예상이 맞는지 확인하는 과정에서 데이터의 이상 여부도 파악할 수 있다. 가령 풍속 데이터가 대부분 0이었다면 바람이 불지 않은 날이 많았다기보다는 제대로 데이터를 측정한 날이 거의 없었다고 해석하는 게 더 타당하다. 이때는 풍속을 변수에서 빼줘야 한다.
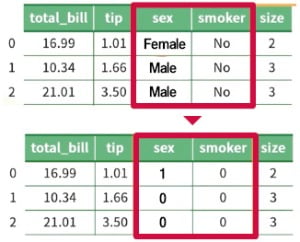
AI가 이해할 수 있는 형태로 데이터를 수정하는 것도 이 단계에서 이뤄진다. 성별 항목이 ‘남성’과 ‘여성’이라고 적혀 있다면 ‘0’과 ‘1’처럼 숫자로 바꿔주는 ‘레이블 인코딩’이 대표적이다. 비어 있는 데이터를 특정 값으로 채우거나 아예 없애기도 한다.
많은 데이터가 있어도 레이블과 관련이 없다면 예측 성능을 떨어뜨린다. 이 때문에 본인이 잘 아는 분야나 업무와 관련한 데이터로 AI에 입문하는 게 가장 좋다. (③에서 계속)
이승우 기자 leeswoo@hankyung.com
-
1
LG CNS는 26일 강원 철원·영월, 전남 완도·무안, 경북 문경 5개 농어촌 지역 학교와 특수학교 등에서 인공지능(AI) 교육 ‘AI 지니어스’를 운영(사진)했다. ...

-
2
AICE 내달 12일 첫 시험…"데이터 해석하고 모델링 연습해야"
다음달 12일 첫 번째 AICE 정기 시험이 치러진다. AICE는 한국경제신문사와 KT가 함께 개발한 인공지능(AI) 교육·평가 도구다. 국내 최초로 마련된 전 국민 대상 AI 평가인 만큼 취업을 준비하...

-
3
"타이타닉 생존자 예측 가능할까"…'캐글'에 모인 전세계 AI 실력자들
“타이타닉 탑승객 일부의 정보와 생존 여부를 알 수 있다면 나머지 탑승객의 생존 여부를 예측할 수 있을까.”데이터 사이언스나 머신러닝을 공부하는 사람이라면 누구나 한 번쯤은 풀어봤을 &lsquo...

![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


