알리바바, 이미지 이해·복잡한 대화 가능 새로운 AI 모델 출시
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트

중국 기술 대기업은 자사의 두 가지 새로운 모델인 Qwen-VL과 Qwen-VL-Chat이 오픈 소스가 될 것이라고 말했다.
또한 전 세계의 연구원, 학계 및 기업이 자체 시스템을 교육할 필요 없이 이를 사용해 자체 AI 앱을 만들 수 있고 시간과 비용을 절약할 수 있다고 설명했다.
알리바바는 Qwen-VL이 다양한 이미지와 관련된 개방형 쿼리에 응답하고 사진 캡션을 생성할 수 있다고 했다.
Qwen-VL-Chat은 여러 이미지 입력을 비교하고 여러 차례의 질문에 답하는 것과 같은 더 복잡한 상호 작용에 초점을 맞추고 있다.
Qwen-VL-Chat이 수행할 수 있는 일부 작업에는 사용자가 입력한 사진을 기반으로 한 스토리 작성, 이미지 생성, 사진에 표시된 수학 방정식 풀기 등이 포함된다.
알리바바의 두 가지 최신 모델은 올해 초 출시된 Tongyi Qianwen이라는 회사의 대규모 언어 모델을 기반으로 구축됐다.
엄수영기자 boram@wowtv.co.kr
-
1
주가 상승·환차익 동시에…KB운용, 'RISE 미국S&P500 엔화노출 ETF' 출시
미국 대표지수 '스탠더드앤드푸어스(S&P)500지수'를 일본 엔화로 투자하는 상장지수펀드(ETF) 'RISE 미국 S&P500엔화노출(합성 H)'이 14일 상장했다.해당 ETF는 미국 주...

-
2
외국인·기관 동반 매도에 멀어지는 2500…코스닥도 '주춤'
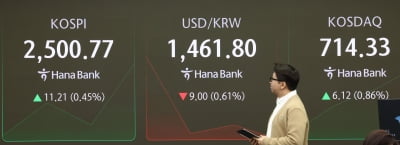
코스피가 외국인과 기관의 동반 매도에 결국 하락전환했다. 코스닥도 오름폭을 줄여 강보합권으로 내려앉았다.14일 오전 10시25분 현재 코스피는 전일 대비 2.98포인트(0.12%) 내린 2486.58에 거래되고 있다...
-
3
엔터주가 강세를 보이고 있다. 주요 기획사에서 신인 아티스트가 데뷔하자 매수세가 몰린 모습이다. 올해 하반기 BTS와 블랙핑크도 활동할 것으로 예상돼 기대감이 커지고 있다.14일 오전 10시18분 현재 JY...


![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


