테크 업체에 떨어진 특명…“AI의 거짓말을 막아라”
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
B2B 서비스에 앞다퉈 탑재
○생성형 AI의 단점 ‘환각 현상’
5일 정보기술(IT) 업계에 따르면 국내외 주요 AI 업체들이 RAG 기술을 자사 기업 간 거래(B2B) 서비스에 도입하고 있다. RAG는 LLM의 한계를 보완하기 위해 고안된 기술이다. 캐나다의 AI 기업 코히어의 패트릭 루이스 박사가 2020년 내놓은 논문에서 RAG라는 용어를 처음 사용했다.
LLM은 방대한 양의 텍스트 데이터를 기반으로 만든 초거대 AI다. 오픈AI의 챗GPT, 구글의 제미나이, 앤스로픽의 클로드, 네이버의 하이퍼클로바X 등이 대표적이다. 언어의 맥락을 이해할 수 있는 트랜스포머 알고리즘이 활용됐다. 이용자가 자연어 형태로 텍스트를 입력하면 학습된 데이터를 활용해 가장 적합한 답변을 제시한다.
문제는 AI가 질문을 제대로 이해하지 못했거나 알맞은 정보가 없을 때다. 이때 LLM은 보유한 데이터 중에서 가장 확률이 높다고 생각하는 정보를 조합해 그럴싸한 답변을 내놓는다. 챗GPT 출시 초기 ‘세종대왕 맥북 던짐 사건’에 대해 설명해달라고 하자 “조선왕조실록에 기록된 일화로 세종대왕이 훈민정음 초고 작성 중 담당자에게 분노해 맥북과 함께 그를 방으로 던진 사건”이라고 답한 것이 대표적인 환각 현상이다. 일반적인 사용자라면 재미로 받아들일 수 있지만 기업 입장에선 심각한 문제일 수 있다. 일부 기업들이 생성형 AI 도입을 주저하는 것도 환각 현상의 영향이 크다.
○맞춤 답안지 따로 제공하는 RAG
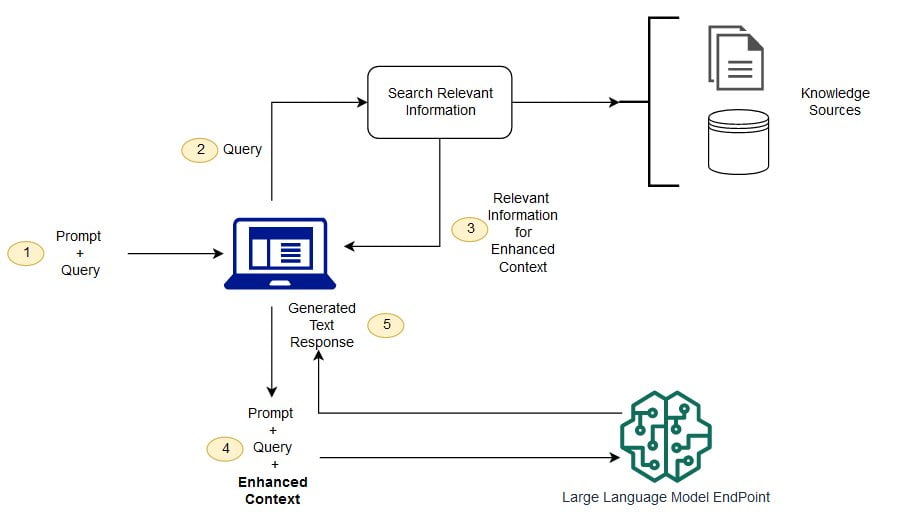
RAG는 LLM이 학습한 데이터와 별개의 외부 데이터를 활용해 답변의 정확도를 높이는 방식이다. 특정 분야의 질문에 답할 수 있는 답안지를 따로 제공한다고 이해하면 된다. 이용자가 질문을 던지면 LLM이 처리하기에 앞서 외부의 데이터베이스와 매칭하는 작업을 거친다. 질문과 관련 있는 데이터를 찾아 LLM으로 보내면 LLM이 사람이 이해하기 쉬운 문장으로 답변을 정리해서 제시하는 식이다.
환각 현상을 피하기 위해 특정 데이터를 LLM에 직접 학습시키는 파인 튜닝 방식도 쓸 수 있지만 비용이 훨씬 많이 든다. 새로운 데이터를 추가할 때도 RAG 기술이 훨씬 간편하다는 설명이다. 파인 튜닝은 매번 새로운 정보를 LLM에 학습시켜야 하지만 RAG는 데이터베이스만 업데이트하면 되기 때문이다.
RAG가 성공하려면 신뢰도 높은 데이터 세트를 확보해야 한다. 기업 내부의 정보를 질문과 쉽게 대조할 수 있도록 데이터베이스를 제대로 구축했는지 여부에 따라 결과물이 달라질 수 있다는 게 업계의 설명이다. 업계 관계자는 “기업에서 AI를 효과적으로 쓰려면 기업 내부의 데이터를 잘 모아 정제하는 작업이 필수적”이라며 “카카오톡을 통한 업무 지시 문구나 양식이 제각각인 엑셀 파일 만으론 RAG 구현이 불가능하다”고 설명했다.
이승우 기자 leeswoo@hankyung.com
-
1
국민 2명 중 1명은 인공지능(AI) 서비스를 경험한 것으로 나타났다.과학기술정보통신부는 이 같은 내용을 포함한 2023년 인터넷이용실태조사 결과를 28일 발표했다.AI 서비스 경험률은 2021년 32.4%에서 20...

-
2
'선거광고' 얼마나 심하길래…작년 한해 730만건 지운 구글
구글이 지난 한 해 동안 자사 정책을 위반한 55억건 이상의 광고를 삭제·차단했다고 밝혔다. 같은 기간 일부 이용자에게만 노출되도록 조치한 광고 건수는 65억개에 달했다. 구글은 27일(현지시...

-
3
베이조스·저커버그, '줄줄이' 팔았다…美증시 정점 신호?
제프 베이조스 아마존 창업자, 마크 저커버그 메타(페이스북·인스타그램 모기업) 최고경영자(CEO) 등 미국 빅테크(대형 정보기술 기업) 거물들이 줄줄이 자사주를 내다 판 것으로 확인됐다. 기술주가 이끌어...


![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


