라이너·올거나이즈 등 스타트업
성능 측정하는 벤치마크 개발
문제 주고 정확도 테스트하는 식
편법으로 순위 끌어올리기도
인공지능 스타트업들이 인공지능(AI) 기술 성능을 측정하기 위한 벤치마크(지표) 개발과 리더보드(순위표) 운영에 나서고 있다. AI 성능 경쟁을 유도하고 관련 시장에서 주도권을 잡겠다는 전략이다.
○시장화된 ‘AI 순위 매기기’
28일 업계에 따르면 AI 검색엔진 라이너는 KAIST 인터랙션 연구실과 공동 연구를 통해 AI 에이전트 시스템의 신뢰도를 측정하는 벤치마크 데이터 세트를 구축할 예정이다. 해외에선 미국 스타트업 시에라가 AI 에이전트의 성능을 평가하는 벤치마크를 공개했다.
AI 앱 마켓을 운영하는 올거나이즈도 검색증강생성(RAG) 기술의 한국어 성능을 평가하는 ‘알리 RAG 리더보드’를 최근 선보였다. 금융·의료 등 5개 분야별로 200~300쪽짜리 문서를 올리고 각 분야에서 사용자가 할 법한 질문 60개를 생성했다. 평가 툴 5개 가운데 3개 이상에서 오류가 없으면 ‘이상 없음’으로 판명하고 점수화한다.
또 다른 AI 스타트업 셀렉트스타는 KAIST 등과 협업한 대규모언어모델(LLM) 벤치마크인 ‘코낫’을 발표했다. 하반기에 코낫 기반 리더보드도 출시할 예정이다.
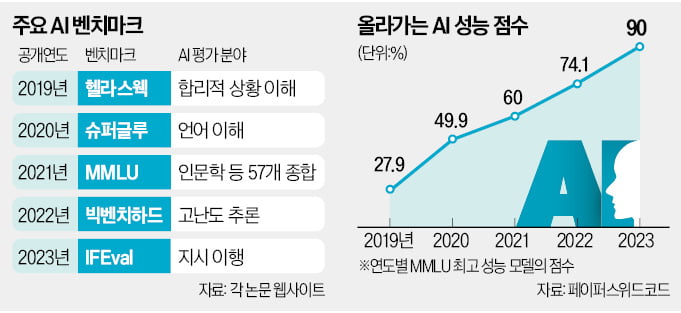
벤치마크는 AI 모델 성능을 측정하고 비교하기 위해 사용하는 평가 데이터다. 리더보드는 여러 벤치마크를 종합해 AI 모델 순위를 매기는 일종의 순위표다. 허깅페이스가 운영하는 ‘오픈 LLM 리더보드’가 가장 유명하다.
초등학교 수준의 과학 문제로 이뤄진 데이터세트 ARC, 합리적 추론 능력을 평가하는 헬라스웩, 57개 주제에 관한 지식 정확도를 테스트하는 MMLU 등의 벤치마크가 적용됐다. 한국엔 한국지능정보사회진흥원(NIA)과 업스테이지가 공동 운영하는 ‘오픈-코-LLM 리더보드’가 있다.
AI업계 관계자는 “경량화 대규모언어모델(sLLM)이 많이 나오면서 성능을 비교하고 싶어하는 수요가 크다”며 “허깅페이스에서 상위권에 오르기 위한 경쟁도 치열하다”고 말했다.
○“새로운 평가 방법 나와야”
순위 경쟁이 심해지다 보니 리더보드 자체의 신뢰도가 떨어졌다는 비판도 나온다. 지난해 12월 국내 스타트업 업스테이지의 ‘솔라’를 기반으로 개발한 모델이 허깅페이스 리더보드 1위부터 10위까지 석권해 주목받았다. 반년이 지난 지금은 같은 순위표의 상위 50위권에서 국내 모델 자체를 찾아보기 어렵다.
업계 관계자는 “벤치마크 데이터는 대부분 공개돼 있다”며 “마음만 먹으면 각 항목에 최적화하는 방식으로 얼마든지 리더보드 순위를 올릴 수 있다”고 했다. 학생이 시험 내용을 제대로 이해하지 못한 채 ‘족보’만 반복해 풀어 좋은 점수를 받고 있었다는 얘기다. AI 발전 속도가 워낙 빨라 시중 모델들이 기존 평가 방식을 이미 뛰어넘었다는 분석도 나온다.
업계에선 완전히 새로운 AI 평가 방법이 필요하다는 목소리가 나온다. 대표적인 시도는 사람이 직접 언어 모델을 평가하는 방식이다. 미국 UC버클리 연구팀은 인간 평가자가 두 AI 모델의 답변 중 더 나은 대답을 직접 선택하도록 해 성능을 평가하고 있다.




![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


