LG, 국내 첫 오픈소스 AI…"구글·메타 한판 붙어보자"
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
한국형 AI 생태계 주도권 확보

LG AI연구원이 7일 경량화 대규모언어모델(LLM)을 내놨다. 2021년 12월 첫 번째 버전을 내놓은 뒤 약 2년8개월 만이다. LG 관계자는 “라마와 젬마 등 다른 오픈소스 AI 모델과 비교해도 성능에 손색이 없다”며 “경량화·최적화 기술 연구에 집중해 초기 모델 대비 성능을 높이면서 모델 크기는 100분의 3으로 줄이는 데 성공했다”고 설명했다.
구광모 회장(사진)은 올해 3월 주주총회에서 “성장 사업은 고객과 시장이 요구하는 핵심 경쟁력을 조기에 확보해 주력 사업화하고, 미래 사업은 AI·바이오·클린테크 분야를 중심으로 속도감 있게 추진해 미래 포트폴리오의 한 축으로 키워가고자 한다”고 강조한 바 있다.
LG가 엑사원3.0을 오픈소스 방식으로 공개한 것은 한국형 AI 생태계를 구축함으로써 AI산업의 주도권을 쥐기 위한 포석이라는 분석이 나온다. 국내에서 자체 생성형 AI를 개발한 곳은 LG와 네이버가 대표적이다.
엑사원3.0은 학습을 위해 사용하는 매개변수가 78억 개에 이른다. AI의 언어로 불리는 토큰 수도 8조 개에 육박한다. 구글 젬마2의 매개변수와 토큰이 각각 90억 개, 8조 개라는 점을 고려하면 글로벌 빅테크의 기술력과 비슷한 수준이다. LG는 엑사원3.0을 LG전자, LG유플러스 등 LG 계열사 제품과 서비스에 곧바로 적용할 예정이다.
전자업계 관계자는 “LG가 경량화 모델에 성공했다는 것은 엔비디아의 AI 반도체에 의존하지 않아도 된다는 의미”라며 “오픈소스를 통해 국내외 AI 엔지니어와 공학도들이 엑사원3.0을 많이 활용할수록 LG의 AI 관련 사업 범위도 넓어질 것”이라고 내다봤다.
김채연 기자 why29@hankyung.com
-
1
[포토] AI 기술로 되살아난 79년 前 '광복의 환희'
79년 전 광복의 환희가 인공지능(AI) 기술로 되살아났다. SK텔레콤은 14일 디지털 프로젝트 ‘815 리마스터링’을 통해 AI 기술로 광복 당시 영상과 음성을 선명하게 복원했다. 1945년 ...
![[포토] AI 기술로 되살아난 79년 前 '광복의 환희'](https://img.hankyung.com/photo/202408/AA.37701095.3.jpg)
-
2
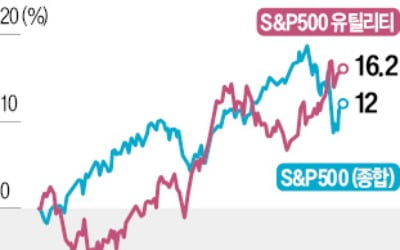
버핏 '돈 먹는 하마'라더니…AI 열풍에 날개 단 유틸리티株
미국 유틸리티 기업들이 올해 매출 가이던스를 잇따라 높여 잡고 있다. 인공지능(AI) 데이터센터 열풍으로 2분기 전력 공급 계약을 여럿 체결한 데 따른 자신감에서다.벤 레빗 S&P글로벌원자재인사이트 전력 및 재생에너...
-
3
젠슨 황 엔비디아 최고경영자(CEO·사진)가 이달에도 7558만달러(약 1028억원) 상당의 엔비디아 주식을 매각했다.13(현지시간) 미국 증권거래위원회(SEC)에 따르면 황 CEO는 지난 1~8일 6거...


![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


