RAG에 RIG 더해 인공지능 환각 없앤다
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
구글, LLM 정확도 향상 위해
검색증강생성에 삽입생성 결합
실시간 정보 반영해 답변 가능
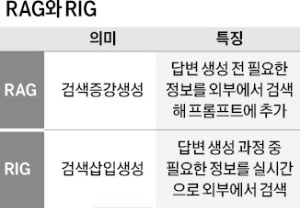
여기에 적용된 RIG 기술은 답변을 생성하는 과정에 필요한 정보를 실시간으로 외부 데이터베이스에서 검색하는 방법이다. 모델이 답변을 만드는 도중에 스스로 자연어 질의를 생성해 외부 데이터베이스에 물어보고, 검색된 결과를 답변에 바로 삽입한다. 예를 들어 “2023년 서울의 평균 기온이 얼마인가”라고 질문하면 RIG는 답변 생성 과정에서 ‘서울의 2023년 기온 데이터’를 외부 데이터베이스에 물어보고 결과를 답변에 포함한다. 즉각적인 데이터 조회가 필요한 상황에 적합하다.
RAG는 RIG와 비슷하지만 순서가 약간 다르다. RAG는 답변 생성 전에 필요한 정보를 외부 데이터베이스에서 먼저 검색해 프롬프트에 추가한다. 가령 “미국과 중국의 이산화탄소 배출량을 비교해줘”라고 물어볼 때 RAG는 외부 데이터베이스에서 미국과 중국의 이산화탄소 배출량 데이터를 먼저 검색한다. 검색 결과를 프롬프트에 입력해 LLM이 더 정확한 답변을 만들도록 유도한다.
두 방식 모두 외부 데이터를 활용해 응답 정보의 정확성과 신뢰성을 높여준다. 하지만 방식의 특성에 따라 장단점이 존재한다. 실시간 정보를 반영하고 동적인 데이터 요청에 유연하게 대응해야 하는 경우엔 RIG가, 대규모 데이터 세트를 기반으로 정확하고 맥락에 맞는 답변을 생성해야 하는 경우엔 RAG가 더 알맞다.
이승우 기자 leeswoo@hankyung.com

ADVERTISEMENT

-
1
“200여 개 협력사와 손잡고 제조 공정 분야 인공지능(AI) 모델을 구축하겠습니다.”김동건 동화엔텍 대표는 지난 16일 부산 강서구 화전공장을 방문한 양재생 부산상공회의소 회장과 부산시 관계자...

-
2
"환율 오르는데 어디에 투자?"…신한은행, 최초 AI 상담 서비스
신한은행이 금융권 최초로 생성형 인공지능(AI) 기술을 기반으로 소비자와 쌍방향 소통이 가능한 투자상담 서비스를 출시한다. 지금도 AI로 금융상품을 추천하거나 관련 뉴스를 정리해주는 서비스는 있지만 정제된 자체 데이...
-
3
롯데에너지머티, 엔비디아 'AI 반도체 공급망' 올라탔다
롯데그룹의 소재 계열사 롯데에너지머티리얼즈가 엔비디아가 주도하는 ‘인공지능(AI) 반도체’ 공급망에 진입했다. 데이터센터와 연결된 고성능 네트워크 장비(스위치)에 차세대 동박을 납품하는 것을 시...

ADVERTISEMENT

![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


