학습량 늘리고 속도 더 빠르게…AI 진화시킬 기술 나왔다
-
기사 스크랩
-
공유
-
댓글
-
클린뷰
-
프린트
서울대 전병곤 교수 연구팀
새 '데이터증강' 기술 발표
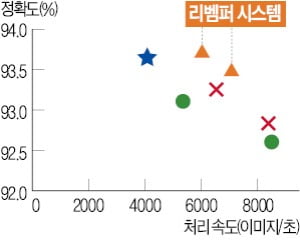
그런데 데이터 증강은 필연적으로 학습 속도 저하를 동반한다. 시험 범위가 넓어지면 준비하는 데 시간이 더 걸리는 것과 같다. 최근 이런 약점을 극복할 수 있는 기법이 개발되고 있다. 전병곤 서울대 컴퓨터공학부 교수 연구팀은 이달 글로벌 컴퓨터 시스템 학회 ‘USENIX ATC’에서 새로운 형태의 데이터 증강 시스템을 발표했다고 30일 밝혔다. 데이터 처리 최적화를 통해 학습량을 늘리면서도 속도를 기존보다 높였다.
전 교수 연구팀은 ‘데이터 리퍼비싱’ 기법을 활용했다. 고기를 익힐 때 초벌구이를 하듯 데이터 증강 과정에 초벌 단계를 도입한 것이다. 이를 통해 AI는 더 빠르고 다양한 학습이 가능해진다. 이와 함께 연구팀은 데이터 표본이 각 학습 단계에 고르게 배분될 수 있는 시스템을 적용했다. 이른바 ‘캐싱 시스템’이다. 데이터 리퍼비싱과 캐싱 시스템을 결합하면 AI는 데이터 공부 시간을 허투루 쓰지 않는 ‘빈틈없는 학생’이 된다.
전 교수는 “데이터 증강 과정을 나눠도 AI의 정확성이 떨어지지 않게끔 하는 것이 과제였다”며 “새로운 캐싱 시스템과 결합해 기존에 보편적으로 쓰이던 모델(파이토치)과 성능이 비슷하게 하면서도 학습 속도는 두 배로 올릴 수 있었다”고 말했다. 앞으로 자연어처리(NLP) 연구에 이 기술을 접목해 음성, 텍스트 등 실제 AI 서비스의 효용을 높인다는 계획이다.
AI의 학습 능력 자체를 끌어올리려는 시도도 많다. 무작정 많은 양의 데이터를 입력하기보다 내재된 핵심 정보를 AI가 배우도록 하는 것이다. 양보다 질에 집중하는 전략이다. 이달 열린 글로벌 AI 학술대회 ‘ICML’에선 ‘신경 활성화 코딩(NAC)’ 기술이 최고 영예인 롱 톡(Long Talk)에 선정됐다. 김건희 서울대 컴퓨터공학부 교수 연구팀이 미국 컬럼비아대와 함께 개발했다. 주어진 데이터에 포함된 핵심 정보를 AI가 스스로 파악하게 하는 기술이다.
김 교수 연구팀은 가공되지 않은 데이터인 ‘비정형 데이터’의 쓰임에 주목했다. 양식이나 단위가 달라도, 핵심 정보들만 AI가 잘 해석할 수 있다면 활용이 가능할 것으로 봤다. 연구팀이 개발한 NAC는 비정형 데이터를 다수 입력받고도 이 중 ‘알짜 데이터’를 파악하고 학습시킬 수 있다. 방대한 시험 범위에서 나올 문제만 골라주는 ‘족집게 강의’를 듣는 것과 비슷하다. 이런 과정을 거치면 AI는 약간의 정형 데이터만 입력받아도 높은 정확도를 갖추게 된다. 김 교수는 “유튜브 동영상 등 주변에 흔히 볼 수 있는 비정형 데이터로도 AI가 학습할 수 있도록 기술을 고도화할 예정”이라고 했다.
이시은 기자 see@hankyung.com

ADVERTISEMENT

-
1
월스트리트 대형 투자은행들이 코로나19 델타 변이 바이러스 확산에도 직원들의 사무실 복귀를 밀어붙이고 있다. 월가를 상징하는 동상 ‘돌진하는 황소(Charging Bull)’와 같은 기세다. 미...
-
2
올림픽은 간절함이다. 오랜 시간 땀 흘려 치열한 경쟁을 뚫고 본선 무대에 올라서다. 선수들은 피나는 노력을 제대로 평가받기 위해 매 순간 절실해진다.하지만 간절하다고 모두가 이길 수는 없다. 승패가 갈린다. 승자는 ...

-
3
[클릭! 한경] 올림픽 선수들 삼성 깜짝 선물에 '환호'
네티즌이 이번주 한경닷컴에서 가장 많이 본 기사는 7월 27일자 <“언빌리버블!”…올림픽 선수들, 삼성 깜짝 선물에 ‘환호’>였다. 삼성전자가 도쿄올림픽에 참가...
![[클릭! 한경] 올림픽 선수들 삼성 깜짝 선물에 '환호'](https://img.hankyung.com/photo/202107/AA.27093997.3.jpg)
ADVERTISEMENT

![K팝 업계에도 '친환경' 바람…폐기물 되는 앨범은 '골칫거리' [연계소문]](https://img.hankyung.com/photo/202206/99.27464274.3.jpg)


