KAIST, 최적의 인공지능 딥러닝 데이터 선택 기술 개발
입력
수정
예측 오류와 훈련 시간 각각 21%, 59% 줄여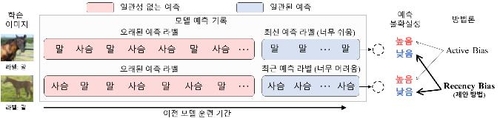
이때 선정된 데이터 샘플을 '배치'(batch)라고 부른다.
배치를 무작위로 선택할 경우 정확도가 떨어지기 때문에 학습에 적합한 데이터를 골라내기 위한 연구가 활발히 진행되고 있다. 연구팀은 데이터 추론 결과를 활용해 현재 모델 학습 단계에 가장 도움이 되는 데이터를 효과적으로 선택할 수 있는 기술을 개발했다.
단계별 추론 단계에서 데이터가 너무 쉬우면 답을 계속 맞히거나, 반대로 너무 어려우면 계속해서 틀리게 되는 일관적인 결과가 나타난다.
이 같은 데이터는 예측 정확도를 높이는 데 도움이 되지 않는다. 반대로 몇 단계에서의 추론 결과가 일관적이지 않다면 데이터 추론이 혼동되고 있다는 뜻으로, 현재 시점에서 난도가 적절한 데이터라고 볼 수 있다.
연구팀은 이 같은 방법론을 '최신 편향'(Recency Bias)이라 이름 붙이고 이를 시각적 이미지를 분석하는 데 사용되는 인공신경망의 한 종류인 '합성 곱 신경망'(Convolutional Neural Network) 학습에 적용했다.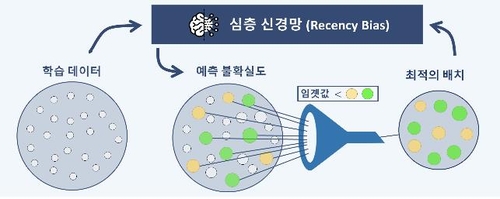
/연합뉴스

이때 선정된 데이터 샘플을 '배치'(batch)라고 부른다.
배치를 무작위로 선택할 경우 정확도가 떨어지기 때문에 학습에 적합한 데이터를 골라내기 위한 연구가 활발히 진행되고 있다. 연구팀은 데이터 추론 결과를 활용해 현재 모델 학습 단계에 가장 도움이 되는 데이터를 효과적으로 선택할 수 있는 기술을 개발했다.
단계별 추론 단계에서 데이터가 너무 쉬우면 답을 계속 맞히거나, 반대로 너무 어려우면 계속해서 틀리게 되는 일관적인 결과가 나타난다.
이 같은 데이터는 예측 정확도를 높이는 데 도움이 되지 않는다. 반대로 몇 단계에서의 추론 결과가 일관적이지 않다면 데이터 추론이 혼동되고 있다는 뜻으로, 현재 시점에서 난도가 적절한 데이터라고 볼 수 있다.
연구팀은 이 같은 방법론을 '최신 편향'(Recency Bias)이라 이름 붙이고 이를 시각적 이미지를 분석하는 데 사용되는 인공신경망의 한 종류인 '합성 곱 신경망'(Convolutional Neural Network) 학습에 적용했다.

/연합뉴스